Reference for the gitflic-ci.yaml file
This documentation lists the keywords for configuring your gitflic-ci.yaml file.
Keywords
| Keywords | Global | For Job | Description |
|---|---|---|---|
stages |
+ | Names and execution order of pipeline stages | |
include |
+ | + | Including external .yaml files into the configuration |
image |
+ | + | Docker image |
cache |
+ | + | List of files and directories to cache between jobs |
variables |
+ | + | Declaring variables and a list of predefined variables available for use |
parallel:matrix |
+ | Creating parallel jobs using a matrix of variables | |
inputs |
+ | Using typed parameters in any part of the configuration file | |
stage |
+ | Defining the stage for a job | |
script |
+ | List of shell scripts to be executed by the agent | |
before_script |
+ | + | List of shell scripts to be executed by the agent before the job |
after_script |
+ | + | List of shell scripts to be executed by the agent after the job |
artifacts |
+ | List of files and directories to be attached to the job on success | |
needs |
+ | Array of job names whose successful execution is required to start the current job | |
when |
+ | Defining job execution conditions | |
rules |
+ | List of conditions to influence field behavior | |
workflow |
+ | Managing pipeline creation and modifying fields | |
tags |
+ | Job tags for the agent | |
allow_failure |
+ | Rule allowing the pipeline to continue in case of job failure | |
except |
+ | Branch names for which the job will not be created | |
only |
+ | Branch names for which the job will be created | |
trigger |
+ | Rule allowing one pipeline to trigger another | |
extends |
+ | Rule allowing configuration inheritance from other jobs or templates | |
environment |
+ | Defines the environment in which deployment from the related job will be performed | |
services |
+ | Run additional Docker containers along with the main task container | |
release |
+ | Creating releases in CI/CD tasks |
stages
Keyword type: Global keyword.
Use stages to define the list of pipeline execution stages.
If stages are not defined in the gitflic-ci.yaml file, the following predefined stages are available by default:
- .pre
- build
- test
- deploy
- .post
The order of stage elements determines the order of job execution:
- Jobs in the same stage run in parallel.
- Jobs in the next stage start after successful completion of jobs in the previous stage.
- If the pipeline contains only jobs in the .pre or .post stages, it will not run. There must be at least one job in another stage. .pre and .post stages can be used in the required pipeline configuration to define matching jobs that should run before or after project pipeline jobs.
Example:
stages:
- build
- test
- deploy
- All stages are executed sequentially. If any stage fails, the next one will not start and the pipeline will end with an error.
- If all stages are successfully completed, the pipeline is considered successfully executed.
include
Keyword type: Global keyword.
You can use include to add additional yaml files.
include:local
Use include: - local to add files located locally in the repository.
By default, the nesting depth is no more than 3 files. To change this, specify the desired value in the
gitflic.ci-cd.include.max-recursion-depthparameter in the fileapplication.properties.
Example:
include:
- local:
- "gitflic-1.yaml"
- "gitflic-2.yaml"
include:project
Use include: - project to add files located in other repositories.
Example:
include:
- project:
project_path: 'my-group/my-project'
ref: v1.0.0
file:
- 'gitflic-ci.yaml'
include:remote
Use include: - remote to add files located in remote repositories.
This feature is available in the self-hosted version of the service
Example:
include:
- remote:
- "https://external/link/file1.yaml"
- "https://external/link/file2.yaml"
include:component
Use include: - component to include components. You can learn more about component functionality here.
include:
- component: $CI_SERVER_FQDN/adminuser/components-project/my-component@1.0.0
Using variables in include
You can use the following variables in the include section:
- Variables declared in the project
- Variables declared in the configuration yaml file
- Predefined variables
- Variables passed via
trigger - Variables declared in the pipeline scheduler
Example:
variables:
project_path: "adminuser/include"
file_path: "file1.yaml"
local_include: "gitflic-1.yaml"
include:
- project:
project_path: '$project_path'
ref: '$CI_COMMIT_REF_NAME'
file:
- 'gitflic-ci.yaml'
- remote:
- "https://external/link/${file_path}"
- local:
- "$local_include"
image
Keyword type: Global keyword. Can also be used as a job keyword.
Use image to specify the Docker image in which the pipeline or job runs. Variables can be used to specify the image.
Global example:
image: maven:3.8.5-openjdk-11-slim
Job example:
job:
stage: build
image: maven:3.8.5-openjdk-11-slim
image:name
Use image:name to specify the name of the Docker image for the job. Equivalent to using the image keyword.
Keyword type: Job keyword.
Supported values: Image name, including registry path if needed, in the following format:
<image-name>:<tag>
Example:
job:
stage: build
image:
name: maven:3.8.5-openjdk-11-slim
image:entrypoint
Use image:entrypoint to specify the command or script as the container entrypoint.
Keyword type: Job keyword.
Supported values: String or array of strings.
Example:
job:
image:
name: maven:3.8.5-openjdk-11-slim
entrypoint: [""]
image:docker
Use image:docker to pass additional options to the GitFlic Runner with Docker type.
Keyword type: Job keyword.
Supported values: Set of additional agent options, which may include:
platform: Selects the image architecture to download. If not specified, defaults to the host architecture.user: Specifies the username or UID to use when running the container.
Example:
job:
image:
docker:
platform: arm64
user: gitflic
Additional information:
image:docker:platform is similar to the --platform option in the docker pull command.
image:docker:user is similar to the --user option in the docker run command.
image:pull_policy
Use image:pull_policy to define the Docker image pull policy.
Keyword type: Job keyword.
Supported values:
always- always pull the imageif-not-present- pull the image only if it is not presentnever- never pull the image
Example:
job:
image:
name: maven:3.8.5-openjdk-11-slim
pull_policy: if-not-present
cache
Keyword type: Global keyword. Can also be used as a job keyword.
The cache keyword allows you to specify a list of files and directories to cache between jobs and pipelines.
The cache is a shared resource at the repository level and is distributed between pipelines and jobs. Note that cache data is restored earlier than artifacts.
cache: []
Use cache: [] to disable cache for a specific job.
cache:paths
To select files or directories to cache, use the paths parameter. This parameter only supports relative paths.
Example:
cache:
paths:
- .m2/repository/
- core/target/
- desktop/target/
cache:key
The key parameter allows you to assign a unique identifier to the cache. All jobs using the same cache key will share the same cache.
If the key is not explicitly specified, the default value is default. This means all jobs with the cache keyword but without an explicit key will use the shared cache with the default key.
Note: The
keyparameter must be used together with thepathsparameter. If paths are not specified, caching will not be performed.
Example:
cache:
key:
- test
paths:
- desktop/target/
Cache usage notes
- The cache is available between different pipelines and jobs. This allows you to reuse data, such as dependencies or compiled files, which can significantly speed up job execution.
- Cache data is restored before artifacts. This ensures cached files are available at early stages of job execution.
- Caching is only supported for files in the project's working directory. You cannot cache files or directories outside the working directory.
variables
Keyword type: Global keyword. Can also be used as a job keyword.
Use variables to declare additional CI/CD variables for the job.
Supported values
- The variable name can contain only digits, Latin letters, and underscores (
_). - The variable value must be a string (enclosed in single
'or double"quotes).
Example:
job_with_variables:
variables:
VAR: "/variable"
scripts:
- echo $VAR
You can nest variable values inside each other. This allows you to create new variables based on existing ones, combining them as needed.
Example:
job_with_variables:
variables:
VAR1: "This_is_my_"
VAR2: "new_var"
scripts:
- VARS=$VAR1$VAR2
- echo $VARS
Notes
- Variables defined in the YAML file are publicly visible, so it is unsafe to define sensitive information in them. Declare variables whose values should not be public via the CI/CD tab in the project settings.
- Variables can be wrapped in curly braces to clearly define the boundaries of the variable.
CI/CD variables
Currently, you can use variables from the following sources in the pipeline configuration (and its jobs):
- Declared via UI in CI/CD settings for the project, team, or company. Such variables can be masked to prevent their values from appearing in logs, increasing security.
- Variables declared in the pipeline scheduler
- Variables declared via UI when creating the pipeline
- Predefined variables.
- Global variables declared in the
variablesfield for the pipeline. These variables are available to all jobs in the pipeline. - Variables declared in the
variablesfield for a job. These variables are available only to the job in which they are declared.
Notes:
- If a variable with the same name is declared in different places, its value will be overwritten according to the CI/CD variable override priority.
Predefined CI/CD variables
| Variable name | Description |
|---|---|
CI_PROJECT_URL |
Project URL for which the pipeline is created (e.g. https://gitflic.ru/project/someuser/some-project-name). |
CI_PROJECT_TITLE |
Project name displayed in the UI (e.g. Some Project Name). |
CI_PROJECT_NAME |
Project directory name (e.g. some-project-name). |
CI_PROJECT_VISIBILITY |
String private or public, depending on project visibility. |
CI_PROJECT_DIR |
Path where the repository is cloned and where the job runs (e.g. /builds/ownername/projectname). |
CI_PROJECT_NAMESPACE |
The alias of the project owner (user, team or company) where the pipeline is running (e.g., adminuser). |
CI_DEFAULT_BRANCH |
Default branch for the project (e.g. master). |
GITFLIC_USER_EMAIL |
Email of the pipeline initiator. |
GITFLIC_USER_LOGIN |
Username of the pipeline initiator. |
CI_COMMIT_REF_NAME |
Branch or tag name on which the pipeline runs (e.g. feature/rules). |
CI_COMMIT_SHA |
Full commit hash on which the pipeline runs. |
CI_COMMIT_TAG |
Tag name on which the pipeline runs. Returns an empty string if the pipeline is not run on a tag. |
CI_COMMIT_MESSAGE |
Commit message. |
CI_COMMIT_TIMESTAMP |
Commit date and time in ISO 8601 format (e.g., 2025-10-13T15:56:21Z). |
CI_PIPELINE_ID |
Pipeline UUID. |
CI_PIPELINE_IID |
Project-local pipeline ID, unique at the project level. |
CI_PIPELINE_TYPE |
Pipeline type. Possible values are listed here |
CI_PIPELINE_SOURCE |
Indicates the source that triggered the current pipeline. Possible values are listed here |
CI_REGISTRY |
Container registry server address, in the format <host>[:<port>] (e.g. registry.gitflic.ru) |
CI_REGISTRY_IMAGE |
Base container registry address, in the format <host>[:<port>]/project/<full project path> (e.g. registry.gitflic.ru/project/my_company/my_project) |
CI_REGISTRY_PASSWORD |
Password for container registry authentication |
CI_REGISTRY_USER |
Username for container registry authentication |
CI_JOB_TOKEN |
Token for accessing artifact/package/release resources via API (used as: --header 'Authorization: token $CI_JOB_TOKEN') |
CI_ENVIRONMENT_NAME |
Environment name in the current job. Available if environment:name is defined in the job. |
CI_ENVIRONMENT_SLUG |
Simplified environment name suitable for DNS, URL, Kubernetes label, etc. Available if environment:name is defined. CI_ENVIRONMENT_SLUG is truncated to 24 characters. An uppercase environment name is automatically suffixed with a random suffix. |
CI_ENVIRONMENT_URL |
Environment URL in the current job. Available if environment:url is defined in the job. |
CI_ENVIRONMENT_ACTION |
Value of environment:action defined for the job. |
CI_ENVIRONMENT_TIER |
Deployment environment tier. Value of environment:deployment_tier defined for the job. |
KUBECONFIG |
The KUBECONFIG variable is set by GitFlic in the CI/CD job runtime environment for Docker-type agents if a Kubernetes agent is connected to the project. The value set by the user takes precedence over the value set by GitFlic. |
CI_SERVER_FQDN |
The fully qualified domain name that identifies the network resource (e.g., localhost:8080) |
CI_SERVER_HOST |
The server host (e.g., localhost) |
CI_SERVER_PORT |
The server port (e.g., 8080) |
CI_SERVER_PROTOCOL |
The server network protocol (http/https) |
CI_SERVER_URL |
The full URL (e.g., http://localhost:8080) |
CI_SERVER_REST_FQDN |
The fully qualified domain name that identifies the network resource for accessing the REST-API (e.g., localhost:8080) |
CI_SERVER_REST_HOST |
The server host for accessing the REST-API (e.g., localhost) |
CI_SERVER_REST_PORT |
The server port for accessing the REST-API (e.g., 8080) |
CI_SERVER_REST_PROTOCOL |
The server network protocol for accessing the REST-API (http/https) |
CI_SERVER_REST_URL |
The full URL for accessing the REST-API (e.g., http://localhost:8080/rest-api) |
CI_SERVER_REST_PREFIX |
The URL prefix required for the REST-API (e.g., rest-api, learn more) |
Predefined CI/CD variables for merge requests
These predefined variables are available in merge pipelines and merge result pipelines, which are created as part of working with merge requests.
| Variable name | Description |
|---|---|
CI_MERGE_REQUEST_ID |
Internal UUID of the merge request |
CI_MERGE_REQUEST_PROJECT_ID |
UUID of the project where the merge request is created |
CI_MERGE_REQUEST_SOURCE_PROJECT_ID |
UUID of the source project of the merge request. Differs from CI_MERGE_REQUEST_PROJECT_ID if the request is created from a fork |
CI_MERGE_REQUEST_PROJECT_PATH |
Path of the project where the merge request is created. Format: project/{ownerAlias}/{projectAlias} |
CI_MERGE_REQUEST_SOURCE_PROJECT_PATH |
Path of the source project of the merge request. Format: project/{ownerAlias}/{projectAlias}. Differs from CI_MERGE_REQUEST_PROJECT_PATH if the request is created from a fork |
CI_MERGE_REQUEST_PROJECT_URL |
URL of the project where the merge request is created. Format: http{s)://{Gitflic_domain}/project/{ownerAlias}/{projectAlias} |
CI_MERGE_REQUEST_SOURCE_PROJECT_URL |
URL of the source project of the merge request. Format: http{s)://{Gitflic_domain}/project/{ownerAlias}/{projectAlias}. Differs from CI_MERGE_REQUEST_PROJECT_URL if the request is created from a fork |
CI_MERGE_REQUEST_SOURCE_BRANCH_NAME |
Source branch name of the merge request |
CI_MERGE_REQUEST_TARGET_BRANCH_NAME |
Target branch name of the merge request |
CI_MERGE_REQUEST_APPROVED |
Returns true if all merge request approval rules are met. Otherwise returns an empty string. |
Possible values for the CI_PIPELINE_SOURCE variable
push- Pipeline was triggered after pushing code to the repository.parent_pipeline- Pipeline was triggered using thetriggerkeyword.schedule- Pipeline was triggered by schedule.web- Pipeline was triggered manually via the web interface.api- Pipeline was triggered via API.merge_request_event- Pipeline was triggered by a merge request event.
Possible values for the CI_PIPELINE_TYPE variable
branch_pipeline- Pipeline created on a branchtag_pipeline- Pipeline created on a tagmerge_request_pipeline- Merge pipelinemerge_result_pipeline- Merge result pipelinetrain_car_pipeline- Merge train
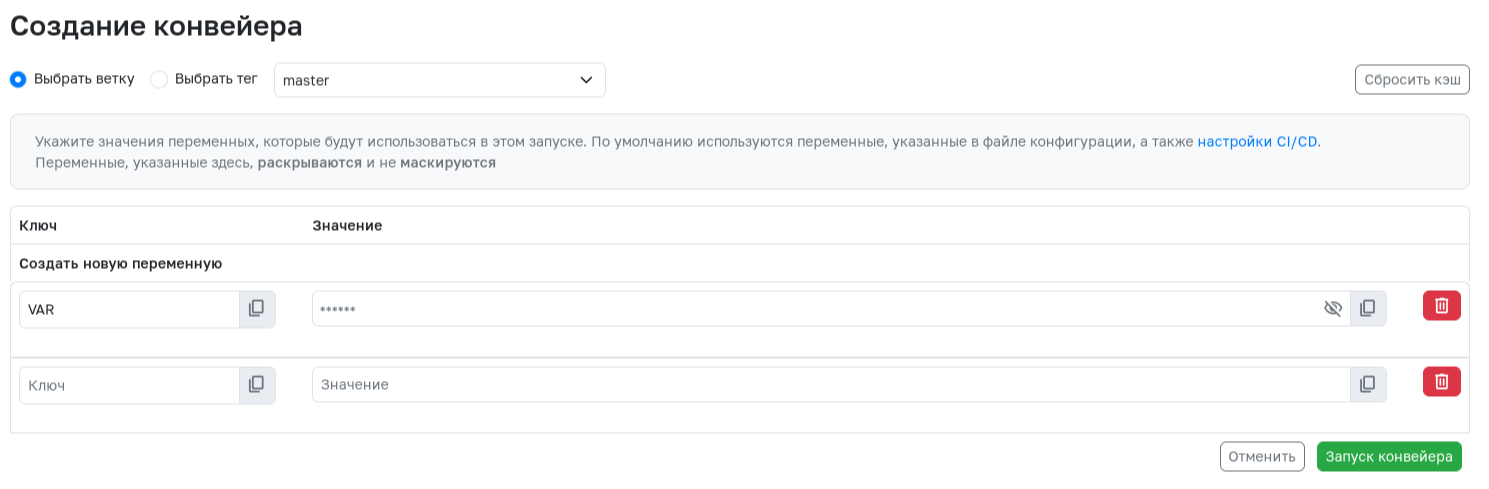
Prefilled variables
When starting a pipeline via the web interface, you can specify prefilled variables. These variables can have unique values for each pipeline. The keywords description, value, and options allow you to prefill the key and value of such variables:
description- required field. Variable description, where you can specify all necessary information. This keyword is required for a standard CI/CD variable to become prefilled.value- optional field. Allows you to specify a default value for the variable, which can be overridden when starting the pipeline.options- optional field. Set of values available for the variable. If this keyword is present, it is not possible to override the variable value. When using this keyword, you must specify one of the possible values in thevaluekeyword.
Prefilled variables are only available at the configuration file level and cannot be defined at the job level.
Example
variables:
VAR1:
description: "Variable without default value"
VAR2:
description: "Variable with default value"
value: "test-value"
VAR3:
description: "Variable with selectable values"
value: "1-value"
options:
- "1-value"
- "2-value"
CI/CD variable override priority
The override priority for different variable sources is as follows (in descending order):
- Variables declared when creating the pipeline or in the pipeline scheduler.
- Variables declared for the project via UI.
- Variables declared in the job when using the
parallel:matrixkeyword in the.yamlconfiguration file. - Variables declared for the job in the
.yamlconfiguration file. - Global variables declared for the pipeline in the
.yamlconfiguration file. - Predefined variables.
Variables with equal priority override each other.
Example of working with different variable types
- A masked variable
POPULAR_VARwith the valuePopular from projectis declared for the project via UI. - In the
variablesfield for the pipeline, the variablePOPULAR_VAR: "Popular from pipeline"is declared, as well as the variableOBSCURE_VAR: "Obscure from pipeline". - In the
variablesfield for the jobjob 0, the variables are declared as follows:POPULAR_VAR: "Popular from job 0",OBSCURE_VAR: "Obscure from job 0". - As a result, for the job
job 0, the variable values will be:POPULAR_VARwill have the valuePopular from projectand will be masked, andOBSCURE_VARwill have the valueObscure from job 0. - The value for
POPULAR_VARfrom the job or pipeline did not override the value declared via UI for the project. The value for the variable declared in the pipeline (OBSCURE_VAR) for the jobjob 0was overridden.
Using CI/CD variables
All CI/CD variables are set as environment variables in the pipeline runtime environment. To access environment variables, use the syntax of your shell.
Bash
To access environment variables in Bash, sh, and similar shells, add the $ prefix to the CI/CD variable:
variables:
MY_VAR: "Hello, World!"
my_job:
script:
- echo "$MY_VAR"
PowerShell
To access environment variables in Windows PowerShell, add the $env prefix to the variable name:
variables:
MY_VAR: "Hello, World!"
my_job:
script:
- 'echo $env:MY_VAR'
inputs
Use inputs to extend CI/CD customization capabilities. inputs and CI/CD variables can be used in an analytical manner but do not have a one-time value.
inputsare typed parameters for governance users utilizing the frontend during pipeline creation. To define specific values when including a configuration file viainclude, useinputsinstead of CI/CD variable substitution.- CI/CD variables provide reusable values that can be shared across multiple levels but cannot be overridden during future pipeline executions. CI/CD variables are recommended for use as secrets or for values that need to be consistent across multiple includes.
Use spec:inputs in a configuration file (use --- to separate the specification from the configuration). This section is intended to define the inputs parameters that users can provide when including the file.
Example:
spec:
inputs:
job-prefix:
default: "production"
description: "Deployment environment"
options: [ "production", "testing", "development" ]
version:
default: "1.0"
type: number
regex: "[0-9]\.[0-9]"
---
$[[ inputs.job-prefix ]]-deploy:
script:
- ./deployment.sh
image: gitflic-$[[ inputs.version ]]
spec.inputs.default
Use the optional spec.inputs.default field to define a default value. When a default value is provided, providing a value for that input when including the configuration is optional. If no default is provided, the input is required when using the include keyword.
Keyword type: Global keyword.
spec.inputs.description
Use the optional spec.inputs.description field to describe the input. The description does not affect the input value but can help users understand the purpose or expected values.
Keyword type: Global keyword.
spec.inputs.options
Use the optional spec.inputs.options field to define a list of allowed values for the input. Providing a value not in the specified list is not allowed.
Keyword type: Global keyword.
spec.inputs.regex
Use the optional spec.inputs.regex field to define a regular expression that the input value must match. Using any value not specified in the template as the value of inputs may cause an error.
Keyword type: Global keyword.
spec.inputs.type
Use the optional spec.inputs.type field to specify the type for the input. Attempting to use any type other than the specified one as the value type of inputs will result in an error. Possible values:
string- String. This is the default if thetypefield is not defined.array- Array.number- Number.boolean- Booleantrueorfalse.
Keyword type: Global keyword.
Using inputs
To use inputs in any part of the .yaml file, use the syntax $[[ inputs.{inputName} ]], where {inputName} is the name of a specific input. When expanding the configuration, the specified construct will be replaced by the standard value from the default field or the value passed within the include keyword family.
When including a file into the configuration using include, you have the option to pass values that will be set for specific inputs defined in the included file. The provided value must be one of the values listed in the options field (if defined) and must match the regex pattern (if defined).
Example:
include:
- local: 'gitflic-1.yaml'
inputs:
job-prefix: "testing"
export_results: true
spec:
inputs:
job-prefix:
default: "production"
description: "Deployment environment"
options: "production, testing, development"
export_results:
default: false
type: boolean
---
$[[ inputs.job-prefix ]]-deploy:
script:
- ./$[[ inputs.job-prefix ]]-deployment.sh
export-job:
rules:
- if: $[[ inputs.export_results ]] == true
script:
- ./export.sh
parallel:matrix
This keyword allows you to define a matrix of variables to create multiple instances of the same job with different values of the specified variables within a single pipeline.
Keyword type: Job keyword.
When using this keyword, consider the following requirements:
- The matrix is limited to 200 created jobs
- In the
needskeyword, you must pass the full name of the matrix job with brackets and variable values, or use the needs:parallel:matrix job keyword
Example
matrix_jobs:
stage: deploy
script:
- echo "here some script"
parallel:
matrix:
- PROVIDER: name1
STACK:
- value1
- value2
- value3
- PROVIDER: name2
STACK: [value4, value5, value6]
- PROVIDER: [name3, name4]
STACK: [value7, value8]
The example generates 10 parallel matrix_jobs, each with different pairs of PROVIDER and STACK values:
deploystacks: [name1, value1]
deploystacks: [name1, value2]
deploystacks: [name1, value3]
deploystacks: [name2, value4]
deploystacks: [name2, value5]
deploystacks: [name2, value6]
deploystacks: [name3, value7]
deploystacks: [name3, value8]
deploystacks: [name4, value7]
deploystacks: [name4, value8]
stage
Use stage to define the stage for a job.
Keyword type: Job keyword.
Example:
stages:
- build
- deploy
job:
stage: build
script
Use script/scripts to specify commands to be executed by the agent.
Keyword type: Job keyword.
Supported values: Array of strings.
job1:
scripts: apt-get update
job2:
scripts:
- apt-get -y install maven
- apt-get -y install git
before_script
Use before_script/before_scripts to specify commands to be executed before the main commands of each job after restoring artifacts.
When using before_script as a global keyword, the commands will be executed before each job.
Keyword type: Job keyword. Can also be used as a global keyword.
Supported values: Array of strings.
Example:
job1:
scripts: apt-get update
before_script:
- apt-get -y install maven
- apt-get -y install git
If any command in the before_script block fails, then:
- all commands in the
scriptsblock will be skipped - jobs in the
after_scriptsblock will be executed
after_script
The after_script/after_scripts keyword allows you to specify commands to be executed after the main job commands.
-
If
after_scriptis defined globally, the specified commands will be executed after each job, regardless of its status. -
If
after_scriptis defined inside a specific job, the commands will be executed only after that job.
Keyword type: Job keyword. Can also be used as a global keyword.
Supported values: Array of strings.
Example:
job1:
scripts: apt-get update
after_script:
- apt-get update
- apt-get -y install maven
- apt-get -y install git
Additional information:
If the job times out or is canceled, after_script commands are not executed.
artifacts
Use artifacts to specify which files to save as job artifacts. Job artifacts are a list of files and directories attached to the job upon execution.
By default, jobs automatically download all artifacts created by previous jobs within the same stage.
When using the needs keyword, jobs can only download artifacts from jobs defined in the needs configuration.
Keyword type: Job keyword.
Supported values: Array of file paths relative to the project directory.
artifacts:paths
Paths are relative to the project directory and must be specified in relative format. Absolute paths or references to files outside the repository directory are not supported.
Example:
artifacts:
paths:
- bin/usr/
- bin/path
- frontend/saw
artifacts:name
Use artifacts:name to set the name of the artifact created as a result of the job.
Example:
artifacts:
name: job_artifacts
paths:
- bin/usr/
- bin/path
- frontend/saw
artifacts:reports
Use artifacts:reports to upload SAST/DAST reports and junit reports.
Junit test report results are displayed on the job's
Teststab.
Keyword type: Job keyword. You can only use it as part of a job.
Supported values: Array of file paths relative to the project directory.
Example:
artifacts:
reports:
sast:
paths:
- sast_report.json
dast:
paths:
- dast_report.json
- dast_report_2.json
junit:
paths:
- target/surefire-reports/*
artifacts:reports:dotenv
Use artifacts:reports:dotenv to pass environment variables as an artifact.
Using scripts, variables are added to a file with the .env extension, the variables are available for use in scripts at subsequent stages of the pipeline.
To use variables from the 'dotenv' file in the stage where they were created, you need to add a dependency to the tasks in the needs of the task where the variables are created.
To prevent tasks from using variables from 'dotenv':
- pass to
needsthe function that creates thedotenvfile and specify theartifacts: falseparameter for it
needs:
- job: job_with_dotenv
artifacts: false
- specify a dependency only on tasks in which a 'dotenv' file was not generated
- pass an empty array to 'needs'.
The variable key in the file must match the regular expression [A-Z0-9_]+
Keyword type: Job keyword. You can only use it as part of a job.
Supported values: Array of file paths relative to the project directory.
Example:
script:
- echo "DOTENV_VARIABLE=value from job" >> test.env
artifacts:
reports:
dotenv:
paths: variables.env
artifacts:expire_in
Use artifacts:expire_in to specify the artifact retention period. After the specified time expires, the artifact will be deleted.
By default, the retention time is specified in seconds. To specify time in other units, use the syntax from the examples:
'55'55 seconds20 mins 30 sec2 hrs 30 min2h30min2 weeks and 5 days9 mos 10 day10 yrs 3 mos and 10dnever
List of artifacts that are not subject to deletion:
- Artifacts from the last pipeline. This behavior can be changed in the service settings
- Locked artifacts. These artifacts will not be deleted until they are unlocked.
- Artifacts with
expire_in: neverset
Example:
job:
artifacts:
expire_in: 1 week
artifacts:when
Use artifacts:when to specify the task result that will trigger the artifact creation.
By default, artifacts are created only in successful tasks.
Possible values:
alwayson_successon_failure
Example:
job:
artifacts:
paths:
- report.txt
when: always
needs
Use needs to specify dependencies between jobs in the pipeline. The needs keyword allows you to explicitly define the execution order of jobs.
Jobs can only download artifacts from jobs defined in needs. Jobs in later stages automatically download all artifacts created in earlier stages if they are specified in needs. When specifying an array of jobs, the job will only run after all specified jobs have completed successfully.
Keyword type: Job keyword.
Possible values: Array of file paths relative to the project directory.
Example:
stages:
- build
- test
build_job:
stage: build
script:
- echo "Building..."
test_job:
stage: test
script:
- echo "Testing..."
needs: [ build_job ]
needs:parallel:matrix
GitFlic supports specifying jobs that work with a matrix.
Jobs can use parallel:matrix to run a job multiple times in parallel within a single pipeline, but with different variable values for each job.
Keyword type: Job keyword.
Example
# Creating a job with a matrix of parameters
job-1:
stage: test
script:
- echo "$PROVIDER"
- echo "$STACK"
parallel:
matrix:
- PROVIDER: ["qqq", "www", "eee"]
STACK: ["111", "222", "333"]
# Job specifying a single matrix job in needs
job-2:
stage: build
needs:
- job: job-1
parallel:
matrix:
- PROVIDER: qqq
STACK: 111
script:
- echo "Building"
# Job specifying multiple matrix jobs in needs
job-3:
stage: build
needs:
- job: job-1
parallel:
matrix:
- PROVIDER: [qqq, www, eee]
STACK: [111, 222, 333]
script:
- echo "Building"
needs:pipeline
Use the needs:pipeline:job to get artifacts in child pipelines created in the same project as the parent ones using the keyword family `trigger:include'.
Keyword type: The keyword for the job.
needs:pipeline - Specify the UUID of the parent pipeline from which to get the artifact in the field. To specify the correct UUID, use the predefined variable $CI_PIPELINE_ID, the value of which must be passed from the parent pipeline.
needs:pipeline:job - In the field, specify the name of the job from the parent pipeline, during which the required artifact is generated.
needs:pipeline:artifacts is an optional field. The default value is true. If the value is false, the required artifact will not be passed to the child pipeline, but the job with this keyword will be available for execution.
Example
child-job:
scripts:
- cat artifact.txt
needs:
- pipeline: $PARENT_PIPELINE_ID
job: parent-job
You can see a working example of transferring artifacts between parent and child pipelines here.
needs:project
Use needs:project to get the artifacts of the specified job.
needs:project - Enter the path to the project with the required artifact in the format {ownerAlias}/{projectAlias} in the field.
| Path variable | Description |
|---|---|
ownerAlias |
Alias of the project owner |
projectAlias |
Project alias |
needs:project:job - Specify the name of the job in the field, during which the required artifact is generated.
needs:project:ref is a link to the git object (branch or tag) on which the job specified in the needs:project:job field was completed.
needs:project:artifacts is an optional field. The default value is true. If the value is false, the required artifact will not be received, but the job with this keyword will be available for execution.
Example
deploy-job:
script:
- echo "Deployment is underway..."
needs:
- project: adminuser/build-project
job: build-job
ref: master
You can see a working example of transferring artifacts between pipelines here.
when
Use when to configure job execution conditions. If not defined in the job, the default value is when: on_success.
Keyword type: Job keyword.
Possible values:
on_success(default): the job will run only if no job in earlier stages has failed or hasallow_failure: truemanual: the job will run only when manually triggered.
Example:
stages:
- build
- test
- deploy
build_job:
stage: build
script:
- echo "Building the project..."
test_job:
stage: test
script:
- echo "Running tests..."
when: on_success
deploy_job:
stage: deploy
script:
- echo "Deploying the project..."
when: manual
only:
- main
rules
Keyword type: Job keyword.
Use rules to control job creation and change their field values based on logical expressions.
rules are evaluated when the pipeline is created. Evaluation is sequential and stops at the first true rule.
When a true rule is found, the job is either included in the pipeline or excluded from it, and job attributes are changed according to the rule.
rules are an alternative to the only/except keywords and cannot be used together.
If a job specifies both rules and only and/or except, pipeline processing will fail with an error.
rules are an array of rules, each consisting of any combination of the following keywords:
A rule from rules is true if the if field is either missing or represents a true logical expression.
A job will be created if:
rulesare not declared or represent an empty array.- The first true rule has
whennot equal tonever.
A job will not be created if:
- None of the rules in
rulesare true. - The first true rule has
when: never.
rules:if
Use rules:if to define the conditions under which a rule is true.
Possible values
An expression with CI/CD variables, namely:
- Comparing a variable to a string.
- Comparing two variables.
- Checking if a variable exists.
- Comparing a variable to a
regex pattern. - Any combination of previous expressions using logical operators
&&or||. - Any previous expression wrapped in
(and).
Comparing a variable to a string
You can use the equality operators == and != to compare a variable to a string.
Both single ' and double " quotes are allowed.
The order of operands does not matter, so the variable can be first, or the string can be first. For example:
if: $VAR == "string"if: $VAR != "string"if: "string" == $VAR
You can compare the values of two variables. For example:
if: $VAR1 == $VAR2if: $VAR1 != $VAR2
You can compare a variable's value to null:
if: $VAR == nullif: $VAR != null
You can compare a variable's value to an empty string:
if: $VAR == ""if: $VAR != ""
You can check if a variable exists:
if: $VAR
This expression is true only if the variable is defined and its value is not an empty string.
Comparing a variable to a regex pattern
You can match regular expressions against a variable's value using the operators =~ and !~.
For regular expressions, the RE2 syntax is used.
The regular expression must be wrapped in slashes /.
The match is true if:
- Operator
=~: at least one substring fully matches the regular expression. - Operator
!~: no substring fully matches the regular expression.
Examples:
if: $VAR =~ /^feature/if: $VAR !~/^feature/
The first expression will be true for the variable value: "feature/rules/if" and false for "base/feature".
The second expression will be false for the first value and true for the second.
Note: single-character regular expressions (such as /./) are not supported and will cause an error.
Another variable can be used as the right operand; its value will be interpreted as a regular expression. For example:
if: $VAR =~ $REGEX_VARif: $VAR !~ $REGEX_VAR
Note: if the variable value is not wrapped in /, it will be interpreted as wrapped (for example, for REGEX_VAR: "^feature" the result will be the same as REGEX_VAR: "/^feature/").
Two expressions can be joined using logical operators:
$VAR1 =~ /^feature/ && $VAR2 == "two"$VAR1 || $VAR2 != "three" && $VAR3 =~ /main$/$VAR1 AND $VAR2$VAR1 OR $VAR2
Expressions can be grouped using ( and ):
$VAR1 && ($VAR2 == "something" || $VAR3 == "something else")
Logical operators and ( ) have the following precedence:
- Expression in parentheses.
- Conjunction of expressions -
&&orAND. - Disjunction of expressions -
||orOR.
Example:
job:
scripts: echo "This job uses rules!"
variables:
VAR1: "one"
rules:
- if: $CI_COMMIT_REF_NAME == $CI_DEFAULT_BRANCH
when: never
- if: $CI_COMMIT_REF_NAME =~ /^feature/ && VAR1 == "one"
allow_failure: true
variables:
VAR1: "one from rule"
VAR2: "two from rule"
- if: $CI_COMMIT_TAG
- when: manual
Four rules are defined for this job:
- The first rule is true if the pipeline is created on the default branch for the project (e.g.
mainormaster). - The second rule is true if the pipeline is created on a branch whose name starts with
featureand the variableVAR1contains the stringone. - The third rule is true if the variable
CI_COMMIT_TAGis declared. - The fourth rule is always true.
If the first rule is true, the job will not be created because when: never.
If the second rule is true and the first is false, the job will be created. The job's allow_failure field will become true, the variable VAR1 will be overwritten, the variable VAR2 will be added to the job, and the job's when field will not be changed.
If the third rule is true and the previous ones are false, the job will be created, and its fields will not be changed.
If none of the previous rules are true, the fourth rule will change the job's when field to manual.
rules:changes
Use rules:changes to determine when to add a job to the pipeline, depending on changes in specific files or directories.
If compare_to is not used, the check for changes will be performed between different git objects depending on the pipeline type:
- Merge pipeline and Merge result pipeline -
rules:changescompares changes between the source and target branches in the merge request. - Branch pipelines and Tag pipelines -
rules:changescompares changes between the commit on which the pipeline is run and the parent commit.
rules:changes:paths
Use rules:changes:paths to specify file paths whose changes are required for the rule to be true.
Keyword type: Job keyword.
The array containing file paths supports the following options:
- Path to a file, which can include CI/CD variables
- Wildcard templates:
- Single directory, e.g.
path/to/directory/* - Directory and all its subdirectories, e.g.
path/to/directory/**/*
- Single directory, e.g.
- Wildcard templates with extensions, e.g.
path/to/directory/*.mdorpath/to/directory/*.{java,py,sh}
Example:
job-build:
script: docker build -t my-image:$CI_COMMIT_REF_NAME .
rules:
- changes:
paths:
- Dockerfile
- build/*
In this example, the job is included in the pipeline if the changes include the file Dockerfile or any file from the build directory.
rules:changes:compare_to
Use rules:changes:compare_to to specify which git objects should be compared when searching for changes in files listed in rules:changes:paths.
Keyword type: Job keyword. Can only be used together with rules:changes:paths.
Supported values:
- Branch name in short
masteror long formrefs/heads/master - Tag name in short
v.4.0.0or long formrefs/tags/v.4.0.0 - Commit hash, e.g.
1a2b3c4
CI/CD variables are supported.
Example:
job-build:
script: docker build -t my-image:$CI_COMMIT_REF_NAME .
rules:
- changes:
paths:
- Dockerfile
compare_to: "develop"
In this example, the job is included in the pipeline if the Dockerfile was changed compared to the develop branch.
rules:allow_failure
If the rule is true and this field is defined, it overwrites the value of the job's allow_failure field.
rules:variables
If the rule is true and this field is defined, it adds variables to the job, potentially overwriting already declared ones.
Possible values: Set of fields in the format VARIABLE_NAME: "variable value".
Example:
job:
variables:
ARGUMENT: "default"
rules:
- if: $CI_COMMIT_REF_NAME == $CI_DEFAULT_BRANCH
variables: # Overwrite the value
ARGUMENT: "important" # of an existing variable
- if: $CI_COMMIT_REF_NAME =~ /feature/
variables:
IS_A_FEATURE: "true" # Define a new variable
scripts:
- echo "Run script with $ARGUMENT as an argument"
- echo "Run another script if $IS_A_FEATURE exists"
| Variable name | Value | Result |
|---|---|---|
GIT_STRATEGY |
none |
Disables repository cloning |
GIT_STRATEGY |
Any except none |
git fetch is applied |
ARTIFACT_DOWNLOAD_STRATEGY |
none |
Disables artifact downloading |
rules:when
If the rule is true and this field is defined, it overwrites the job's when field value.
Possible values
never- the job will not be added to the pipelinemanual- the job is executed only when manually triggered from the UI.on_success- the job is executed only if all jobs withallow_failure: falsecompleted successfully.
workflow
Use workflow to manage the creation of pipelines.
Keyword type: Global keyword.
workflow:rules
Use workflow:rules to manage the creation of pipelines and change the values of their fields based on logical expressions. workflow:rules are calculated before the pipeline is created. The calculation takes place sequentially, stopping at the first true rule. When the true rule is found, the pipeline will either be created or not, and the task attributes will also change in accordance with this rule.
The set of rules inside workflow:rules is identical to rules except:
- Affects the creation of the pipeline as a whole, rather than a single task.
- When using the keyword
workflow:rules:when, the following values are possible -alwaysandnever. If you use any others, a configuration file parsing error will occur. - The value of predefined variables
CI_PIPELINE_IDandCI_PIPELINE_IIDis not available because the pipeline has not yet been created at the calculation stage ofworkflow:rules.
The pipeline will be created if:
workflow:rulesis not declared or is an empty array.- The first true rule is
when: always.
The pipeline will not be created if:
- None of the rules in workflow:rules are true.
- The first true rule is
when: never.
Example:
workflow:
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
variables:
VAR1: 'true'
build:
stage: build
scripts:
- echo "Variable VAR1 = $VAR1"
tags
Use tags to configure the agent.
You can specify tags for a particular agent in its settings. Variables can be used to specify tags.
Keyword type: Job keyword.
Possible values: Array of tag names.
Example:
job:
tags:
- test
- build
allow_failure
Use allow_failure to determine whether the pipeline should continue if the job fails.
-
To allow the pipeline to continue with subsequent jobs, use
allow_failure: true. -
To prevent the pipeline from running subsequent jobs, use
allow_failure: false.
Keyword type: Job keyword.
Possible values:
truefalse(default value)
For
manualjobs, which are executed only when manually triggered from the UI, the default value istrue
allow_failure:exit_codes
Using allow_failure:exit_codes is suitable for managing job statuses when a job can complete with one of the specified exit codes. The job is set to allow_failure: true for any of the listed exit codes and allow_failure: false for any other exit code.
When an exception is triggered, the job in the interface will be displayed with a "Warning" status, and the pipeline will continue executing other jobs.
Keyword Type: Job-level keyword.
Supported Values:
- Single value
- Array of values
Example:
test_job_1:
script:
- echo "Executing script with exit code 1. This job will fail."
- exit 1
allow_failure:
exit_codes: 137
test_job_2:
script:
- echo "Executing script with exit code 137. This job will complete with warning. Pipeline will continue executing jobs."
- exit 137
allow_failure:
exit_codes:
- 137
- 255
except
Use except to specify branches on which the job will not be created.
Keyword type: Job keyword.
Possible values: Array of branch names.
Example:
job:
except:
- master
- deploy
only
Use only to specify branches on which the job will be created.
Keyword type: Job keyword.
Possible values: Array of branch names.
Example:
job:
only:
- master
trigger
Use trigger to configure pipeline triggering from another pipeline.
For cross-project triggers to work properly, the user initiating the pipeline must have at least the developer role in the child project.
A single job cannot contain both
scriptandtriggerkeywords simultaneously.
Please note
The maximum depth for child pipeline calls is 3
Keyword type: Job keyword.
trigger:project
trigger:project - Specifies the project where the pipeline should be triggered.
trigger:branch - Specifies the branch for which the pipeline will be triggered in the project specified in trigger:project.
trigger:strategy - Defines the relationship between the job and child pipeline. If omitted, the trigger job completes immediately after creating the child pipeline without waiting for its successful execution.
Possible values:
depend: Requires successful completion of the child pipeline for the trigger job to succeed.
trigger:forward - Specifies which variables should be passed to the triggered project.
Possible values:
yaml_variables:true(default) orfalse. Whentrue, variables defined in the triggering pipeline (both global and job-level) are passed to child pipelines.pipeline_variables:trueorfalse(default). Whentrue, variables defined in the pipeline scheduler that created the triggering pipeline are passed to child pipelines.
Example:
trigger-project:
trigger:
project: adminuser/cicd-child
branch: master
strategy: depend
forward:
yaml_variables: true
pipeline_variables: true
trigger:include
The trigger:include keyword family allows creating child pipelines within the same project as the parent pipeline. Multiple trigger:include types can be used in a single trigger job - all specified configuration files will be merged into one to create the child pipeline. These keywords function similarly to include.
trigger:include:local
trigger:include:local- Creates a child pipeline based on repository files specified by absolute paths.
Example:
trigger-child:
trigger:
include:
- local:
- "gitflic-1.yaml"
strategy: depend
forward:
yaml_variables: true
pipeline_variables: true
trigger:include:project
-
trigger:include:project- Creates a child pipeline based on files from another repository. Required fields: -
project_path- Project path in{ownerAlias}/{projectAlias}format
| Path Variable | Description |
|---|---|
ownerAlias |
Project owner alias |
projectAlias |
Project alias |
ref- Git reference (branch or tag) where the file should be locatedfile- Absolute path to the configuration file for the child pipeline
Example:
trigger-child:
trigger:
include:
- project:
project_path: 'adminuser/cicd-child'
ref: master
file:
- 'gitflic-1.yaml'
strategy: depend
forward:
yaml_variables: true
pipeline_variables: true
trigger:include:remote
Available in self-hosted service versions
trigger:include:remote- Creates a child pipeline based on remotely hosted files specified by URL.
trigger-child:
trigger:
include:
- remote:
- https://gitflic.ru/project/adminuser/cicd-child/blob/raw?file=gitflic-ci.yaml
strategy: depend
forward:
yaml_variables: true
pipeline_variables: true
trigger:include:artifact
trigger:include:artifact- Implements dynamic pipeline functionality - creates child pipelines based on configuration files generated in other CI/CD jobs. Specifies the artifact filename to use for child pipeline creation. The file must be within an artifact generated by the job specified intrigger:include:job.trigger:include:job- Specifies the job that generates the artifact containing the child pipeline configuration file.
Peculiarities when jobs are in one stage.
If both artifact-generating and trigger jobs are in the same stage, the trigger job must use the needs keyword referencing the artifact-generating job. For jobs in different stages, needs is optional.
stages:
- artifact
- trigger
job-parent:
stage: artifact
scripts:
- echo -e 'from-artifact-job:\n scripts:\n - echo "$CI_PIPELINE_SOURCE"' > gitflic-1.yaml
artifacts:
paths:
- gitflic-1.yaml
job-trigger:
stage: trigger
trigger:
include:
- artifact: gitflic-1.yaml
job: job-parent
strategy: depend
forward:
yaml_variables: true
pipeline_variables: true
Transfer of artifacts between parent and child pipelines
Depending on the type of child pipeline (created in the same project as the parent pipeline or another one), certain keywords should be used to transfer artifacts between pipelines.
When using the trigger:include keyword family, the child pipeline will be created in the same project as the parent pipeline. To transfer artifacts generated in the parent pipeline to the child pipeline, use keyword needs:pipeline.
Example of the parent pipeline configuration
build-artifact:
stage: build
scripts:
- echo "Example for an artifact" >> artifact.txt
artifacts:
paths:
- artifact.txt
job-trigger:
stage: deploy
trigger:
include:
- local:
- "gitflic-1.yaml"
variables:
PARENT_PIPELINE_ID: $CI_PIPELINE_ID
Example of a child pipeline configuration
deploy-job:
stage: build
script:
- cat artifact.txt
needs:
- pipeline: $PARENT_PIPELINE_ID
job: build-artifact
When using the keyword trigger:project, a child pipeline will be created in the specified project. To transfer artifacts generated in the parent pipeline to the child pipeline, use the keyword needs:project.
Example of the parent pipeline configuration
build-artifacts:
stage: build
script:
- echo "Example for an artifact" >> artifact.txt
artifacts:
paths:
- artifact.txt
job-trigger:
stage: deploy
trigger:
project: adminuser/child-project
Example of a child pipeline configuration
deploy-job:
stage: deploy
script:
- cat artifact.txt
needs:
- project: adminuser/parent-project
job: build-artifacts
ref: master
Optimization of the yaml configuration file
It is possible to simplify and reduce duplication in the configuration .yaml files by using:
- Keyword
extends - YAML markup functions such as anchor or
!references
extends
Use extends to inherit task configuration from other tasks or templates. If there are the same keywords in the template/task and the main tasks, the keywords from the main task will be used.
Keyword type: The keyword for the task.
The keyword stage must be specified for the main task, otherwise the task will be displayed in the default stage `test'.
Example:
.default_template:
before_script:
- echo "Executing before_script"
script:
- echo "Executing script"
build_job:
stage: build
extends: .default_template
script:
- echo "Building the project"
- make build
Configuration after using the template
build_job:
stage: build
before_script:
- echo "Executing before_script"
script:
- echo "Building the project"
- make build
Anchor
Use the YAML markup function anchor to reuse keywords from other tasks or templates. If there are the same keywords in the template/task and the main tasks, the keywords from the main task will be used. If you use multiple anchors with duplicate keywords, the keywords from the first anchor will be used.
As an anchor, you cannot specify a task from an external .yaml file added to the configuration using the [include] keyword family(#job.include). To reuse fields from external tasks, use the YAML tag !references.
To mark an issue as an anchor, use the construction &{anchorName} after the name of the issue. To access the anchor task, you must specify the anchor name in the format *{anchorName}.
To fully reuse the anchor, merges must be performed using the construction <<: *{anchorName}.
Example:
.build_template: &build_anchor
stage: build
script:
- echo "Executing script"
build_job:
<<: *build_anchor
image: build-img
Configuration after using the template
build_job:
image: build-img
stage: build
script:
- echo "Executing script"
To use an anchor as part of an array, refer to it in the array element - *{anchorName}. Anchors with keywords containing arrays are only available for use.:
Example:
.deploy_template: &deploy_anchor
- echo "Preparing the environment"
- echo "Deploing"
deploy_job:
stage: deploy
scripts:
- *deploy_anchor
- echo "Close connection"
Configuration after using the template
deploy_job:
stage: deploy
scripts:
- echo "Preparing the environment"
- echo "Deploing"
- echo "Close connection"
!references
Use the YAML tag !references to reuse keywords from other tasks or templates. The following keywords are available for reuse:
Reuse of fields using !references is possible both from tasks declared in a single .yaml file, and added to configurations using the [include] keyword family(#job.include).
Example:
.setup:
script:
- echo "Creating environment"
include:
- local: configs.yaml
.teardown:
after_script:
- echo "Deleting environment"
test:
script:
- !reference [.setup, script]
- echo "Some testing"
after_script:
- !reference [.teardown, after_script]
Configuration after using the template
test:
script:
- echo "Creating environment"
- echo "Some testing"
after_script:
- echo "Deleting environment"
environment
Use environment to define the environment in which deployment from the related job will be performed.
Keyword type: Job keyword.
environment:name
Use environment:name to define the environment name.
Keyword type: Job keyword.
Possible values: The environment name may contain only letters, digits, "-", "_", "/", "$", "{", "}", ".", and spaces, but cannot start or end with "/".
It may contain CI/CD variables, including predefined variables, as well as project, company/team-level variables, and variables declared in gitflic-ci.yaml.
Example:
deploy to production:
stage: deploy
script:
- make deploy
environment:
name: production
Note: If the environment specified in environment:name does not exist, it will be created when the job is executed.
environment:url
Use environment:url to define the environment URL.
Keyword type: Job keyword.
Possible values: Valid URL, e.g. https://prod.example.com.
May contain CI/CD variables, including predefined variables, as well as project, company/team-level variables, and variables declared in gitflic-ci.yaml.
Example:
deploy to production:
stage: deploy
script:
- make deploy
environment:
name: production
url: https://prod.example.com
environment:description
Use environment:description to define the environment URL.
Keyword type: Job keyword.
Possible values: A line of text. The limit is 600 characters.
May contain CI/CD variables, including predefined variables, as well as project, company/team-level variables, and variables declared in gitflic-ci.yaml.
Example:
deploy to production:
stage: deploy
script:
- make deploy
environment:
name: production
url: https://prod.example.com
description: "Here is prod-based enviroment"
environment:on_stop
Stopping the environment can be performed using the on_stop keyword defined in the environment.
It declares another job that is executed to stop the environment.
Keyword type: Job keyword.
Possible values: Name of an existing job.
Example:
deploy to production:
stage: deploy
script:
- make deploy
environment:
name: production
url: https://prod.example.com
on_stop: stop_production
stop_production:
stage: deploy
script:
- make delete-app
when: manual
environment:
name: production
action: stop
environment:action
Use environment:action to describe how the job will interact with the environment.
Keyword type: Job keyword.
Possible values: One of the following keywords:
start- Default value. Indicates that the job creates the environment and deployment.prepare- Indicates that the job only prepares the environment. Deployment is not created.stop- Indicates that the job stops the environment.verify- Indicates that the job only verifies the environment. Deployment is not created.access- Indicates that the job only accesses the environment. Deployment is not created.
Example:
stop_production:
stage: deploy
script:
- make delete-app
when: manual
environment:
name: production
action: stop
environment:deployment_tier
Use deployment_tier to define the environment deployment tier.
Keyword type: Job keyword.
Possible values: One of the following options:
productionstagingtestingdevelopmentother
Example:
deploy:
stage: deploy
script:
- make deploy
environment:
name: customer-portal
deployment_tier: production
Note: The default value is other. It will be set for the environment if environment:deployment_tier is missing.
environment:auto_stop_in
Use auto_stop_in to manage the automatic stopping of an environment via a timer.
Keyword Type: Job-level keyword.
Possible Values: A timer based on natural language, accepting the following time units:
50 seconds20 mins 30 sec2 hrs 30 min5 hours2h30min2 weeks and 5 days9 mos 10 day10 yrs 3 mos and 10dnever
Important!
Time units must be specified from larger (year) to smaller (second).
Default value if the keyword is not present in the job: never
services
Keyword type: Job keyword.
Use the services keyword to start additional Docker containers together with the main job container, for example, to run a database or other auxiliary services.
Services defined in the job are started in the same isolated network as the main container and are only available within that job.
Example:
job:
stage: test
image: ubuntu:latest
services:
- postgres:latest
You can use services in extended syntax with additional parameters. In this case, the name directive must be specified for each service.
When using extended syntax, all directives of the image keyword are supported.
services:name
Use services:name to specify the image for the additional container.
services:
- name: postgres:latest
- name: mysql:latest
services:command
Use services:command to specify the command to run the additional container.
services:
- name: docker:dind
command: ["--tls=false"]
services:alias
Use services:alias to specify the name by which the container will be available on the network.
services:
- name: docker:dind
command: ["--tls=false"]
alias: docker
If alias is not specified, the container will be available by automatically generated names.
In the example:
services:
- tutum/wordpress:latest
Available names:
- tutum__wordpress
- tutum-wordpress
If both names are already taken, the job will fail at runtime.
Docker-in-Docker support
To correctly run an additional container with the docker:dind image, you need to configure the agent to run containers in privileged mode in the agent configuration.
docker.privileged=true
Note that using an additional container with the docker:dind image when the docker.didEnable=true parameter is enabled may lead to incorrect behavior.
release
Use release to create releases during CI/CD job execution.
Keyword support
This keyword is supported only by runner in Docker mode when specifying the image registry.gitflic.ru/company/gitflic/gcli:latest.
Keyword type: Job keyword.
Example:
stages:
- release
release-job:
rules:
- if: $CI_COMMIT_TAG
image: registry.gitflic.ru/company/gitflic/gcli:latest
stage: release
release:
name: "v5.0.0"
description: "Release 5.0.0"
tag_name: "$CI_COMMIT_TAG"
script:
- echo "Creating release $CI_COMMIT_TAG"
release.name
Use name to specify the name of the release being created. Maximum length is 40 characters.
Keyword type: Job keyword.
release.description
Use description to specify the description of the release being created.
Keyword type: Job keyword.
release.tag_name
Use tag_name to specify the name of the tag on which the release will be created. If a tag with the specified name does not exist, it will be automatically created on the commit where the pipeline was triggered.
Keyword type: Job keyword.
Automatic Translation!
This page has been translated using automated tools. The text may contain inaccuracies.