Работа с монорепозиториями в GitFlic
В данной документации будут рассмотрены возможные способы обеспечения простоты и комфорта при разработке крупных монорепозиториев с использованием системы контроля версий Git и платформы GitFlic. Будут рассмотрены следующие темы:
- Sparse-checkout и sparse-index (Разряженная проверка и разряженный индекс)
- Partial clone (Частичное клонирование)
- Shallow clone (Поверхностное клонирование)
Данные способы будут проверены при работе с репозиторием ядра linux, а также достаточно крупными репозиториями VSСode и Rust.
Характеристики данных репозиториев на момент проведения анализа:
-
Linux kernel
Количество коммитов: 1293367
Количество файлов: 85719
Размер проекта: 6.7 GB
Размер репозитория: 5.2 GB -
Rust
Количество коммитов: 261340
Количество файлов: 48640
Размер проекта: 1.6 GB
Размер репозитория: 1.3 GB -
VSCode
Количество коммитов: 123190
Количество файлов: 7448
Размер проекта: 1 GB
Размер репозитория: 0.84 GB
Стоит также понимать, что время, требуемое для выполнения команд и загрузки репозиториев, зависит от пропускной способности канала передачи, а также скорости интернета.
Полное клонирование
Для дальнейшей возможности проведения сравнительного анализа производительности вышеописанных способов прежде всего необходимо замерить стандартные показатели команды git clone.
Таблица 1. Показатели выполнения клонирования репозитория командой git clone.
| Репозиторий | Время клонирования | Размер проекта | Размер репозитория | Количество файлов |
|---|---|---|---|---|
| Linux kernel | 847 sec | 6.7 GB | 5.2 GB | 85719 |
| Rust | 173 sec | 1.6 GB | 1.3 GB | 48640 |
| VSCode | 76 sec | 1 GB | 0.84 GB | 7448 |
Sparse-checkout
Данная команда позволяет абстрагироваться от работы с огромным репозиторием в контексте одного необходимого модуля или нескольких модулей, тем самым создавая ощущение работы в маленьком репозитории.
Например, у нас есть тестовый проект со следующей структурой:
- Директория клиента, которая содержит зависимости для 3 различных платформ: Android, компьютерных ОС, а также iOS
- Сервисная часть, которая содержит в себе всю сервисную логику для нескольких независимых микросервисов.
- Веб-части приложения, в которой хранятся какие-то статические веб странички, используемые JavaScript.
Также стоит отметить, что в корне проекта лежат несколько файлов, это важно учесть.
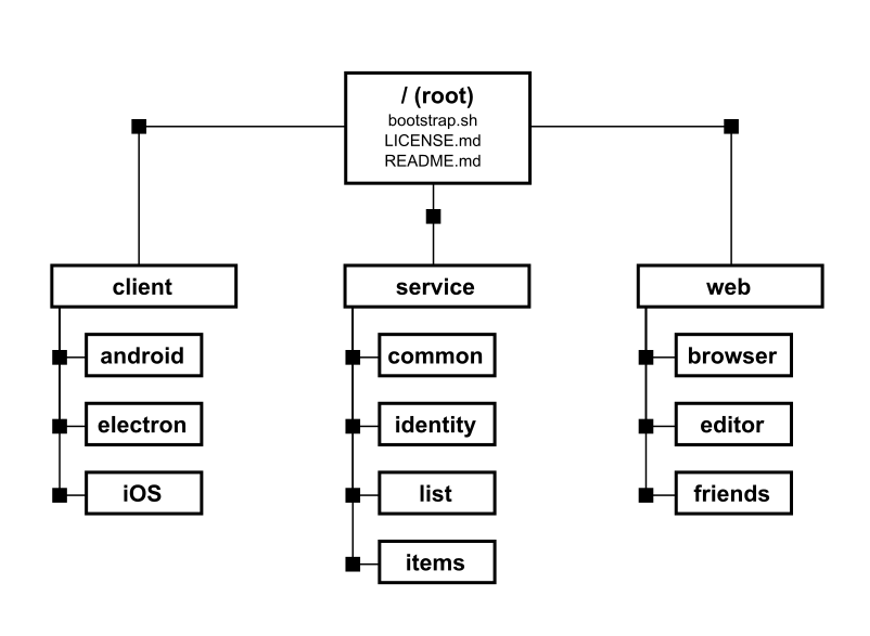
Каждый из этих подмодулей может иметь вложенность вплоть до 10 уровня при этом отдельному разработчику, например, необходимо работать только с определённым модулем.
Для того, чтобы создать видимость работы только с ним, необходимо выполнить следующий набор команд, перейдя в папку проекта:
$ cd <target>
$ git sparse-checkout init --cone
$ git sparse-checkout set <dir1> <dir2> ... <dirN>
README.md, .gitignore и т.д.).2. Вторая команда задает директории, которые мы хотим видеть в проекте, причем директории будут добавляться на основании регулярных выражений-флагов, которые похожи на флаги, используемые в
.gitignore файле.В нашем случае разработчику нужна только директория
client/android, поэтому набор команд будет выглядеть так:
$ cd test_project
$ git sparse-checkout init --cone
$ git sparse-checkout set client/android
/*
!/*/
/client/
!/client/*/
/сlient/android/
ВАЖНО: Т.к. данная команда была использована на уже имеющемся полном репозитории, мы имеем именно видимость работы с маленьким репозиторием, хотя на самом деле абсолютно все файлы проекта уже у нас есть, поэтому для получения максимальной выгоды необходимо выполнить клонирование в стиле sparse mode.
Клонирование в стиле sparse mode
Для того, чтобы клонировать пустой репозиторий, не переключаясь на рабочую ветку, необходимо поставить флаг --no-cheсkout, выглядеть код будет следующим образом:
$ git clone --no-checkout https://gitflic.ru/project/user/test_project.git
$ cd test_project
$ git sparse-checkout init --cone
$ git checkout master
Как работать только с необходимым модулем без лишних файлов?
Предположим, мы являемся андроид разработчиком. Судя по диаграмме, для нашей полноценной работы нам необходима лишь директория android, которая находится в модуле client. Для того, чтобы не работать с остальными ненужными модулями, мы можем выполнить так называемое разряженное клонирование
$ git clone --no-checkout https://gitflic.ru/user/test_project.git
$ cd test_project
$ git sparse-checkout init cone
$ git sparse-checkout set client/android
$ git checkout master
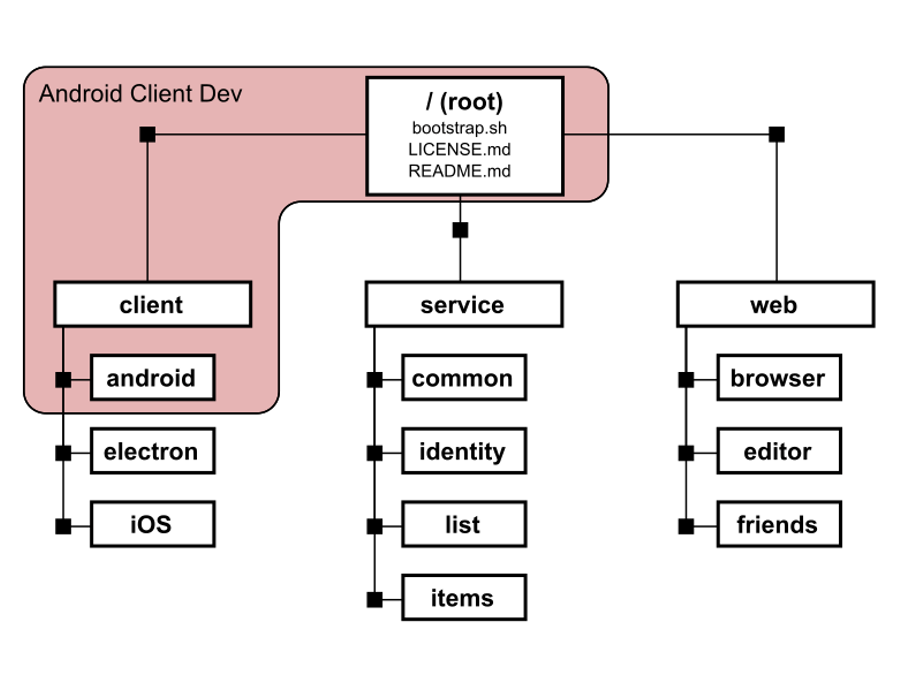
Таким образом, мы будем иметь лишь нужные нам для разработки модуля файлы, а также сможем работать полноценно с системой контроля версий, получая новые изменения, относящиеся только к нашему модулю, и отправляя новые изменения в удалённый репозиторий.
Плюсы и минусы использования sparse-checkout
Основным и самым большим плюсом является то, что при использовании sparse-checkout команда git pull будет обновлять не все файлы, которые есть в проекте, а только те, которые находятся в границах sparse-checkout.
Так, весь Linux репозиторий имеет 91347 файлов, и даже если не во все из них вносились изменения, то при вызове команды git pull git вытянет все файлы и применит изменения к локальной версии.
В нашем же случае вместо обновления 91347 файлов необходимо обновить лишь 2849 файлов, что в десятки раз меньше, а значит и выполнится гораздо быстрее.
Из минусов стоит отметить следующее: для того, чтобы догрузить какие-либо файлы, необходимо наличие интернета и подключения к удаленному серверу, без подключения к серверу локальный git не сможет догрузить необходимую часть проекта и нужные файлы из удалённого репозитория.
Для получения максимально выгодного результата можно комбинировать sparse-checkout и partial clone.
Совместное использование partial clone и sparse checkout.
Первоначально, для понимания что из себя представляет partial clone, перейдите по ссылке и прочитайте о нем отдельно.
Вкратце - команда partial clone позволяет клонировать не весь репозиторий целиком, а только какую-то его часть в зависимости от параметров, переданных во флаге --filter.
Рассмотрим наш вариант: выполним клонирование репозитория с флагом --filter=blob:none при этом не переключаясь на ветку, на которую указывает HEAD (в нашем случае ветка master), для этого добавим флаг --no-checkout
Выполним все необходимые команды:
$ git clone --filter=blob:none --no-checkout https://gitflic.ru/project/user/test_project.git
Клонирование в «test_projectl»...
remote: Counting objects: 10226773, done
remote: Finding sources: 100% (7443598/7443598)
remote: Getting sizes: 100% (341114/341114)
remote: Compressing objects: 100% (29493/29493)
remote: Total 7443598 (delta 5984837), reused 7443571 (delta 5984826)
Получение объектов: 100% (7443598/7443598), 1.45 ГиБ | 8.95 МиБ/с, готово.
Определение изменений: 100% (5984837/5984837), готово.
$ cd test_project
$ git sparse-checkout init --cone
$ git checkout master
remote: Counting objects: 15, done
remote: Finding sources: 100% (15/15)
remote: Getting sizes: 100% (15/15)
remote: Compressing objects: 100% (972780/972780)
remote: Total 15 (delta 0), reused 10 (delta 0)
Получение объектов: 100% (15/15), 262.31 КиБ | 9.71 МиБ/с, готово.
Updating files: 100% (15/15), готово.
Уже на «master»
Эта ветка соответствует «origin/master».
$ git sparse-checkout set client/android
remote: Counting objects: 52, done
remote: Finding sources: 100% (52/52)
remote: Getting sizes: 100% (51/51)
remote: Compressing objects: 100% (378195/378195)
remote: Total 52 (delta 1), reused 22 (delta 1)
Получение объектов: 100% (52/52), 116.16 КиБ | 2.42 МиБ/с, готово.
Определение изменений: 100% (1/1), готово.
Updating files: 100% (52/52), готово.
client/android.
Посмотрим характеристики, полученные в результате выполнения данных команд для репозитория linux, а также других двух репозиториев, выбрав рандомные директории:
Таблица 2. Результат выполнения partial clone совместно с sparse-checkout
| Репозиторий | Время клонирования | Размер проекта | Размер репозитория |
|---|---|---|---|
| Linux kernel | 145 sec | 1.8 GB | 1.7 GB |
| Rust | 45 sec | 526 MB | 509 MB |
| VSCode | 16 sec | 311 MB | 227 MB |
Как можно заметить, время клонирования уменьшилось в 6-7 раз по сравнению с клонированием всего репозитория, при этом размер проекта уменьшился практически в 4 раза, поскольку теперь мы имеешь лишь необходимые для работы файлы.
Как запустить такой проект?
Стоит понимать, что такой способ работы невероятно удобен, однако если в отдельном подмодуле не будет всех необходимых зависимостей, то проект не запустится, поскольку остальные файлы так и буду лежать в удаленном репозитории. Это нельзя отнести ни к плюсам, ни к минусам использования команд, скорее необходимо осознавать, знать это и помнить об этом при работе в таком ключе.
Что такое partial clone и как работать с --filter?
Как уже описывалось выше, команда partial clone совместно с флагом --filter позволяет копировать лишь часть репозитория.
Для удобства введем символьные обозначения объектов git:
- Blob - блобы будут обозначаться квадратами. Представляют из себя содержимое файлов.
- Tree - объекты дерева будут обозначаться треугольниками. Представляют и себя директории в проекте.
- Commit - коммиты будут обозначаться кругами. Это снимки состояния репозитория в момент времени.
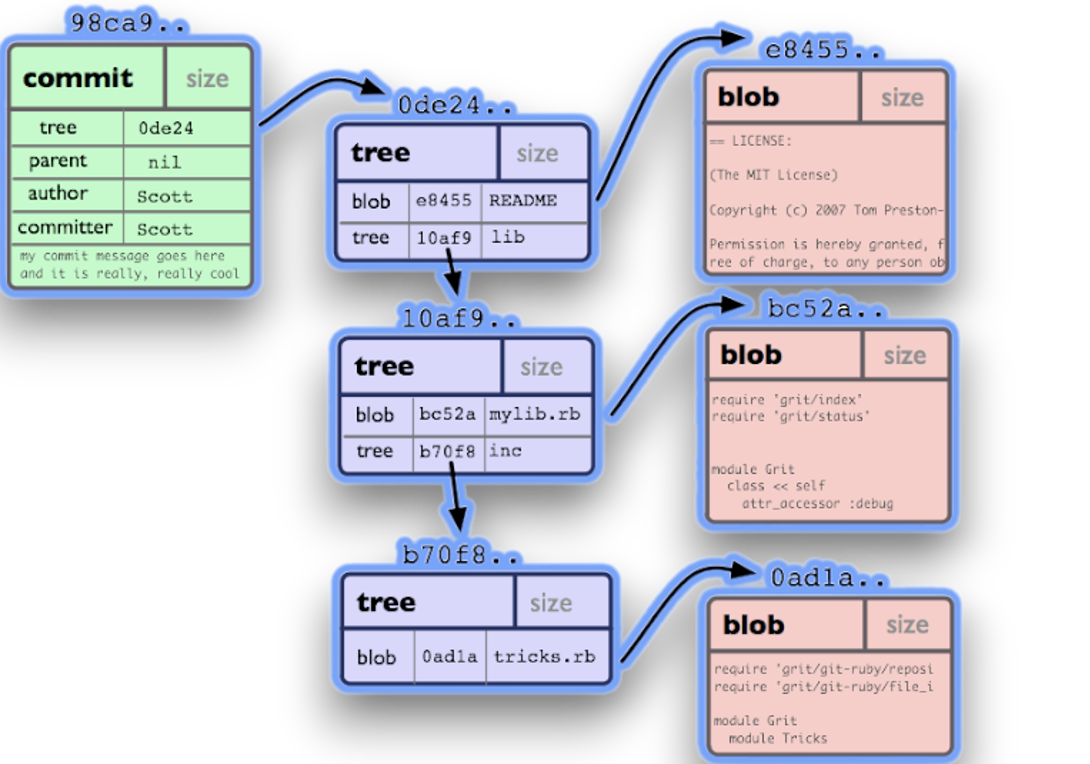
Существует 3 основных способа уменьшить размер клонируемого репозитория:
* git clone --filter=blob:none <url> создает так называемый "Клон без блобов" (blobless clone). Такой способ лучше всего подходит для постоянной разработки.
* git clone --filter=tree:0 <url> создает так называемый "Клон без деревьев" (treeless clone). Такие проекты отлично подходят для случаев, когда проект будет удален после единоразовой сборки, но при этом необходим доступ к истории изменений (по сути графу коммитов).
* git clone --depth=1 <url> Создает поверхностный клон (shallow clone).
Разберем каждый способ отдельно. Такой способ подходит только для единоразовой сборки, постоянная разработка в таком случае слишком неудобна и дорога с точки зрения догрузки объектов.
Разберем каждый способ отдельно, а также посмотрим на время, затрачиваемое для выполнения команд.
Клонирование без блобов (Blobless clone)
Данный способ загружает информацию по всем доступным из корня репозитория коммитам и деревьям БЕЗ блобов, при этом загружает сами блобы "по запросу". Это значит, что первоначально блобы не буду загружены, их загрузка произойдёт при непосредственном обращении к ним при выполнении команды git checkout. Это также включает в себя первый checkout при выполнении команды git clone.
Важно отметить, что при загрузке мы клонируем блобы, которые относятся к дереву коммита, на который ссылается HEAD, однако другие блобы из истории изменений не загружаются, при этом данные деревьев и коммитов в полном объеме присутствуют.
Стоит добавить, что такие команды, как git log или git merge-base не провоцируют загрузку блобов и выполнение этих команд будет давать достоверный результат, ведь мы загружаем всю историю коммитов.
Схематично это будет выглядеть следующим образом:
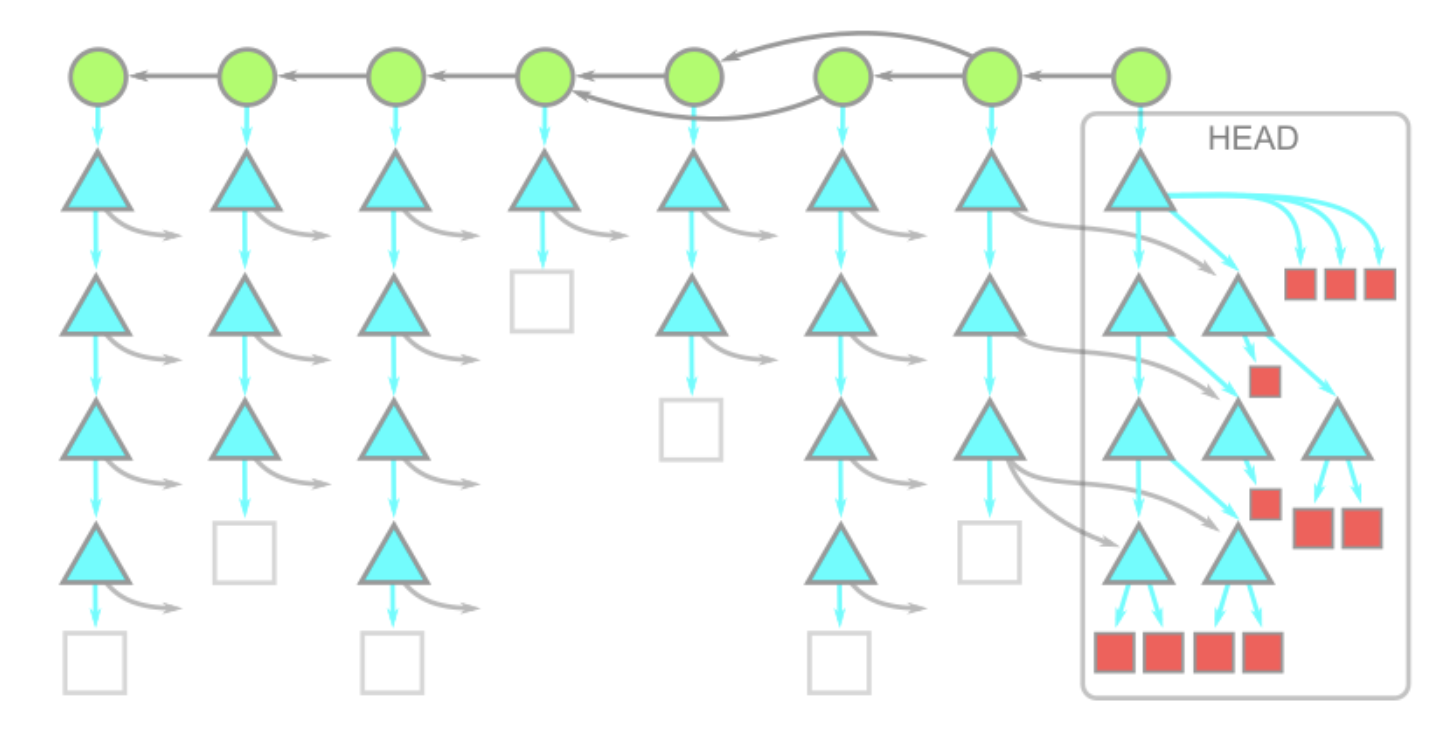
В последующем, при использовании команд git fetch или git pull с удаленного репозитория будет приходить информация только об изменениях в коммитах или деревьях. Новые блобы будут загружаться ТОЛЬКО при использовании git checkout.
Загрузка блобов будет вызываться в любом случае, когда нужно будет содержимое файлов, поэтому такие команды, как git diff или git blame <path> будут вызывать эту самую загрузку блобов.
Однажды загруженные блобы остаются в репозитории, поэтому любая загрузка требует единожды прогрузить содержимое файлов.
Выполним загрузку linux репозитория таким способом:
$ git clone --filter=blob:none https://gitflic.ru/project/user/linux_kernel.git
Клонирование в «linux_kernel»...
remote: Counting objects: 10325225, done
remote: Finding sources: 100% (7517591/7517591)
remote: Getting sizes: 100% (343546/343546)
remote: Compressing objects: 100% (3778/3778)
remote: Total 7517591 (delta 6046838), reused 7517585 (delta 6046836)
Получение объектов: 100% (7517591/7517591), 1.46 ГиБ | 8.43 МиБ/с, готово.
Определение изменений: 100% (6046838/6046838), готово.
remote: Counting objects: 85266, done
remote: Finding sources: 100% (85266/85266)
remote: Getting sizes: 100% (76628/76628)
remote: Compressing objects: 100% (493686/493687)
remote: Total 85266 (delta 8707), reused 68251 (delta 8638)
Получение объектов: 100% (85266/85266), 250.81 МиБ | 5.01 МиБ/с, готово.
Определение изменений: 100% (8707/8707), готово.
Updating files: 100% (85764/85764), готово.
Таблица 3. Результат выполнения git clone --filter=blob:none
| Репозиторий | Время клонирования | Размер проекта | Размер репозитория |
|---|---|---|---|
| Linux kernel | 177 sec | 3.5 GB | 2 GB |
| Rust | 49 sec | 816 MB | 542 MB |
| VSCode | 16 sec | 360 MB | 233 MB |
Клонирование без деревьев (Treeless clone)
Данный способ клонирования загружает всю историю коммитов, при этом блобы и деревья загружаются "по запросу", то есть при непосредственной необходимости. В таком случае схематически проект будет выглядеть следующим образом.
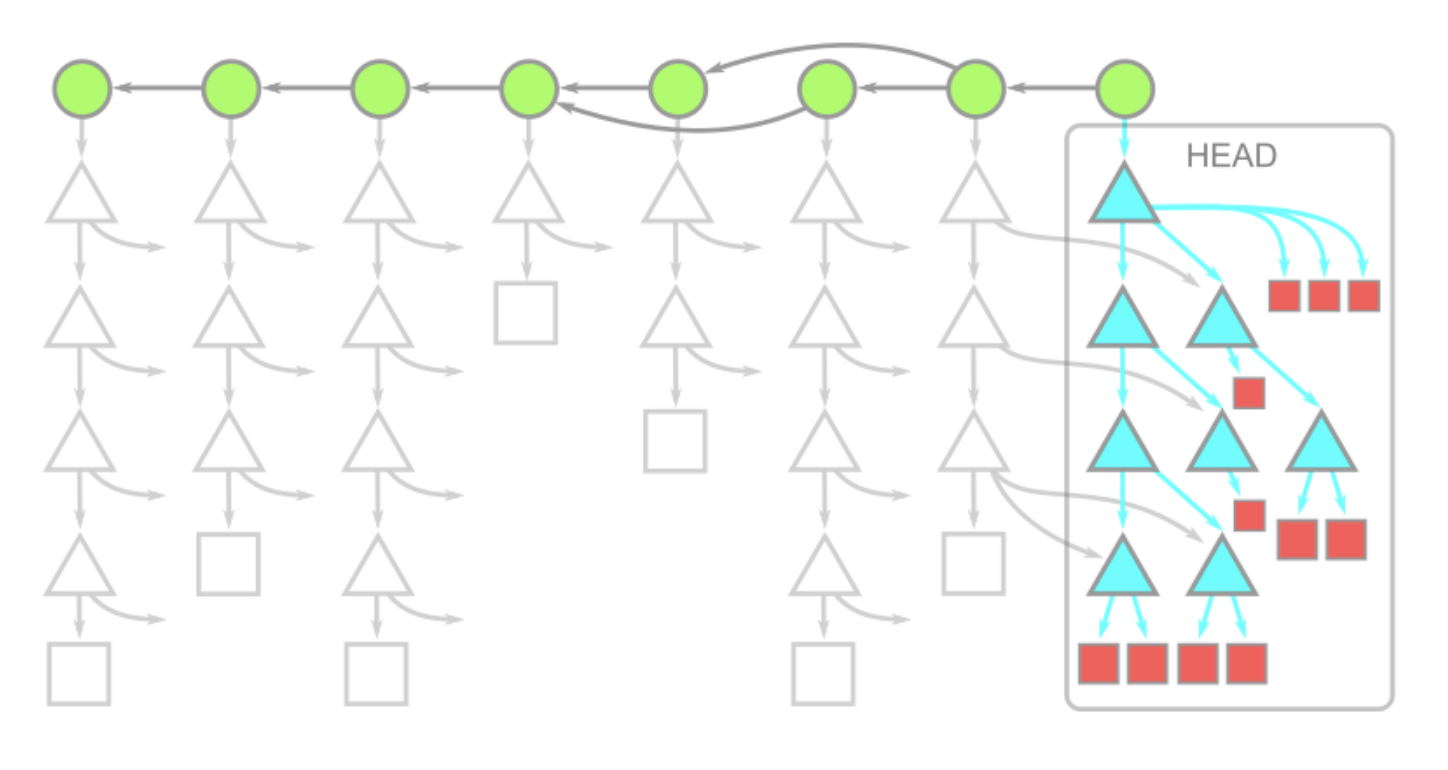
Как и при клонировании без блобов, коммит, на который указывает HEAD, загружается полностью, вместе со всеми деревьями и блобами, но все остальные объекты имеют только данные о самом коммите. Это означает, что клонирование без деревьев может выполниться ЗНАЧИТЕЛЬНО БЫСТРЕЕ, чем клонирование без блобов или полное клонирование.
Аналогично клонированию без блобов, команды git pull и git fetch будут клонировать только информацию об изменениях в коммитах. Однако, работа в таком ключе будет сложнее, поскольку загружать дополнительную информацию для деревьев с блобами тяжелее и дороже, нежели загружать только блобы.
Аналогично, команда git checkout является триггером для загрузки деревьев из удаленного репозитория, причем, запрашивая корневое дерево для коммита, git также запрашивает и все остальные деревья, которые находятся внутри этого корневого дерева, что и составляет всю дороговизну использования.
Команды git merge-base и git log используют только информацию о коммитах, поэтому их использование не будет являться триггером для загрузки деревьев. Однако использование команды git log --<path> будет загружать деревья для всех достижимых коммитов, это стоит помнить!
Если в проекте есть сабмодули, то клонирование без деревьев не очень хорошо с ними работает, поскольку вызов git fetch будет провоцировать загрузку всех деревьев для коммитов, поскольку git будет пытаться найти изменения для сабмодулей. Чтобы избежать этого, необходимо прописать следующее в проекте:
$ git config fetch.recurseSubmodules false
Выполним клонирование без деревьев для репозитория linux и остальных репозиториев, а также посмотрим на результаты.
$ git clone --filter=tree:0 https://gitflic.ru/project/user/linux_kernel.git
Клонирование в «linux_kernel»...
remote: Counting objects: 2572793, done
remote: Finding sources: 100% (1293369/1293369)
remote: Total 1293369 (delta 166160), reused 1293367 (delta 166160)
Получение объектов: 100% (1293369/1293369), 660.71 МиБ | 8.69 МиБ/с, готово.
Определение изменений: 100% (166160/166160), готово.
remote: Counting objects: 90910, done
remote: Finding sources: 100% (5644/5644)
remote: Getting sizes: 100% (5635/5635)
remote: Compressing objects: 100% (2664734/2664734)
remote: Total 5644 (delta 11), reused 3239 (delta 9)
Получение объектов: 100% (5644/5644), 2.64 МиБ | 17.89 МиБ/с, готово.
Определение изменений: 100% (11/11), готово.
remote: Counting objects: 85266, done
remote: Finding sources: 100% (85266/85266)
remote: Getting sizes: 100% (76628/76628)
remote: Compressing objects: 100% (493686/493687)
remote: Total 85266 (delta 8707), reused 68251 (delta 8638)
Получение объектов: 100% (85266/85266), 250.81 МиБ | 8.94 МиБ/с, готово.
Определение изменений: 100% (8707/8707), готово.
Updating files: 100% (85764/85764), готово.
Аналогично клонированию без блобов, мы имеем несколько "получений объектов", поскольку выполняем checkout в контексте выполнения команды git clone, что видно, исходя из кода.
Таблица 4. Результат выполнения git clone --filter=tree:0
| Репозиторий | Время клонирования | Размер проекта | Размер репозитория |
|---|---|---|---|
| Linux kernel | 52 sec | 2.5 GB | 978 MB |
| Rust | 10 sec | 422 MB | 149 MB |
| VSCode | 4 sec | 199 MB | 73 MB |
Поверхностное клонирование (Shallow clone)
Partial clone относительно новая вещь для git в сравнении с поверхностным клонированием. Поверхностное клонирование использует флаг --depth=<N> для того, чтобы обрезать историю коммитов. Например, при --depth=1 мы получим проект с одним коммитом. Лучше всего использовать это совместно с флагами --single-branch --branch=<branch>, чтобы гарантировать загрузку данных только одного коммита, который нам нужен здесь и сейчас.
Схема проекта в таком случае выглядит так:
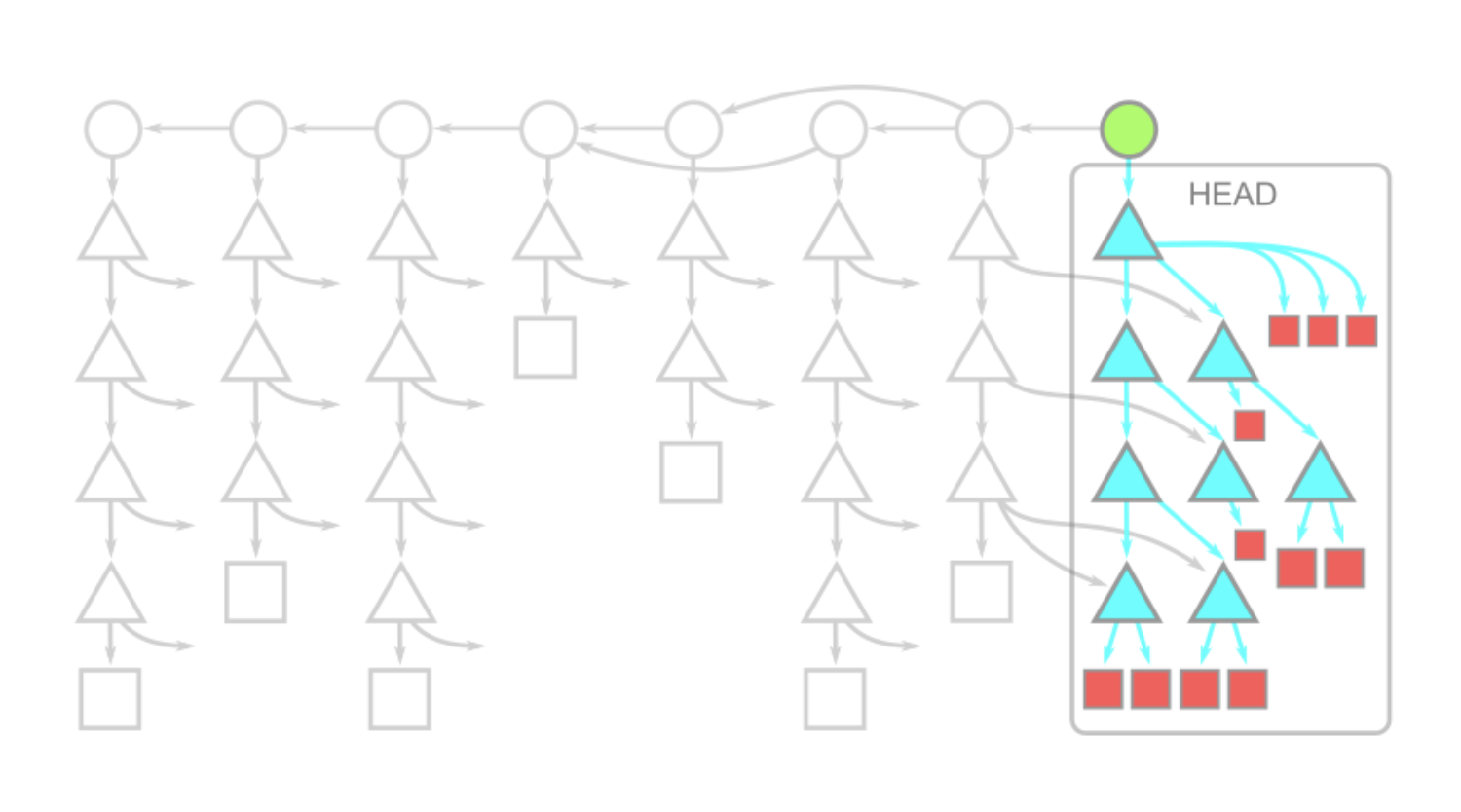
Из-за того, что история коммитов обрезана, команды git merge-base и git log будут давать не тот результат, который вы получите при полном клонировании.
Другая особенность заключается в работе команды git fetch при использовании поверхностного клонирования. При отправке новых коммитов сервер должен предоставить каждое дерево и блоб, которые являются «новыми» для этих коммитов по сравнению с поверхностными коммитами. Это вычисление может быть более дорогостоящим, чем обычная выборка. В зависимости от того, как другие разработчики вносят свой вклад в ваш удаленный репозиторий, операция git fetch в поверхностном клоне может в конечном итоге загрузить почти полную историю коммитов.
Собственно поэтому не рекомендуется использовать поверхностное клонирование кроме случаев, когда репозиторий будет удален после единоразовой сборки.
Выполним поверхностное клонирование репозиториев и посмотрим на результаты:
$ git clone --depth=1 https://gitflic.ru/project/user/linux_kernel.git
Клонирование в «linux_kernel»...
remote: Counting objects: 90911, done
remote: Finding sources: 100% (90911/90911)
remote: Getting sizes: 100% (82263/82263)
remote: Compressing objects: 100% (496274/496289)
remote: Total 90911 (delta 9510), reused 71490 (delta 8647)
Получение объектов: 100% (90911/90911), 253.50 МиБ | 8.59 МиБ/с, готово.
Определение изменений: 100% (9510/9510), готово.
Updating files: 100% (85764/85764), готово.
Таблица 5. Результат выполнения git clone --depth=1
| Репозиторий | Время клонирования | Размер проекта | Размер репозитория |
|---|---|---|---|
| Linux kernel | 19 sec | 1.8 GB | 268 MB |
| Rust | 2.7 sec | 314 MB | 41 MB |
| VSCode | 2 sec | 147 MB | 21 MB |
Итоги
Пробежимся тезисно по разобранным командам:
- Поверхностное клонирование удаляет историю коммитов, из-за чего ломается
git logиgit merge-base. Никогда не выполняйтеgit fetch, если используете его. - Клонирование без деревьев содержит только историю коммитов, но загружать новые деревья достаточно дорогостояще. Однако, при таком способе
git logиgit merge-baseработают корректно, но команды по типуgit log -- <path>очень медленные и не рекомендуются к использованию при таком клонировании. - Клонирование без блобов содержит в себе все достижимые коммиты и деревья, поэтому git загружает только содержимое файлов при необходимости. Это означает, что команды
git blameмедленнее при их первом вызове. Однако, это отличный способ начать работу с огромным репозиторием с большим количеством крупных старых файлов. - Полное копирование работает как ожидается от него. Однако, время загрузки всех данных и место, занимаемое на диске, слишком велико.